O que você recebe
Sessões reais, recibos reais
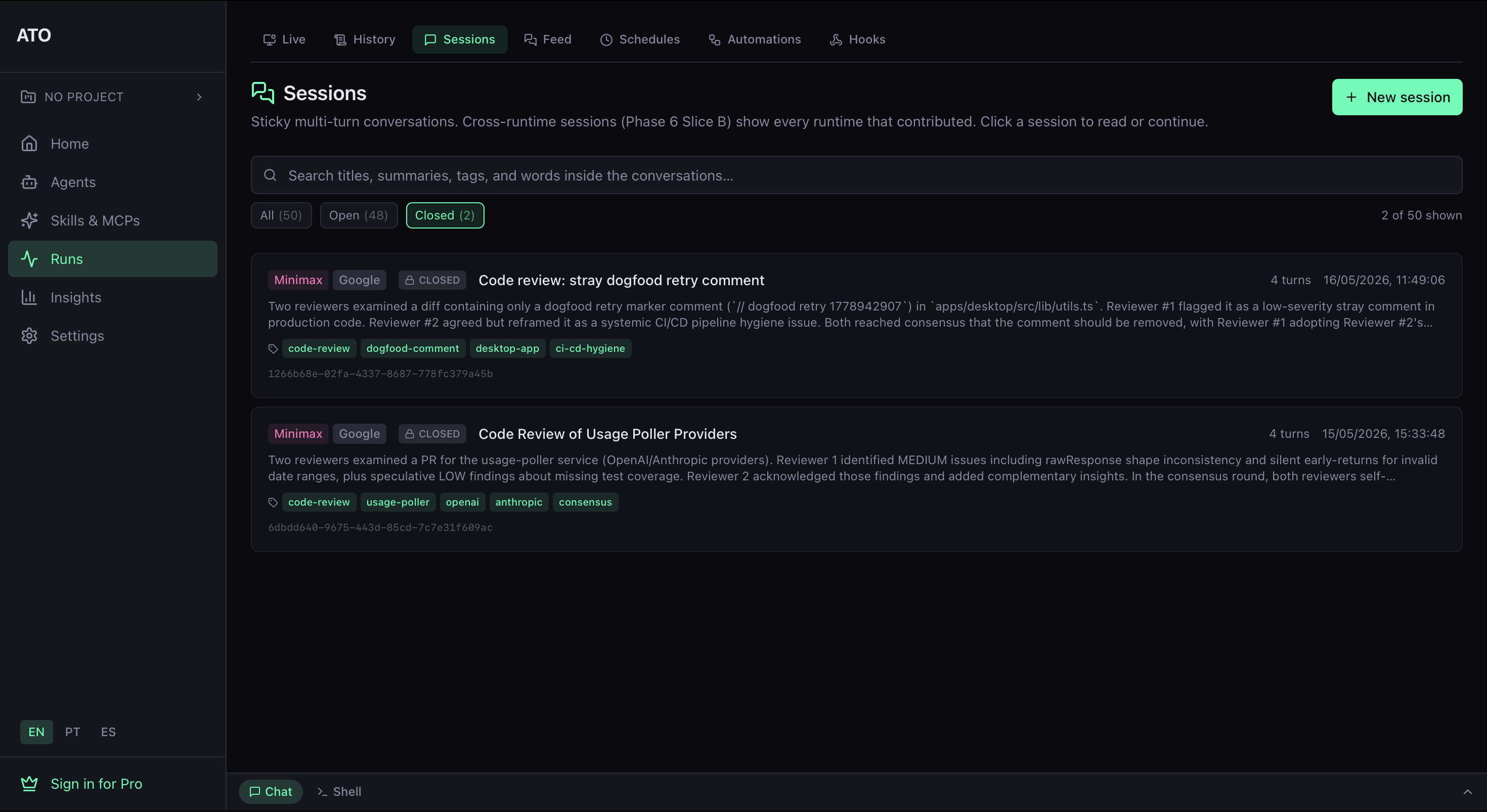
Cada dispatch multi-LLM cai no seu SQLite local como uma sessão que você pode revisar depois. Cada linha carrega um resumo auto-gerado, os runtimes que falaram, as personas (quando você usou --agent), tags e um session id que você pode passar para ato sessions get do terminal. Sem contas, sem round-trip de nuvem — tudo na máquina do desenvolvedor.