Lo que recibes
Sesiones reales, recibos reales
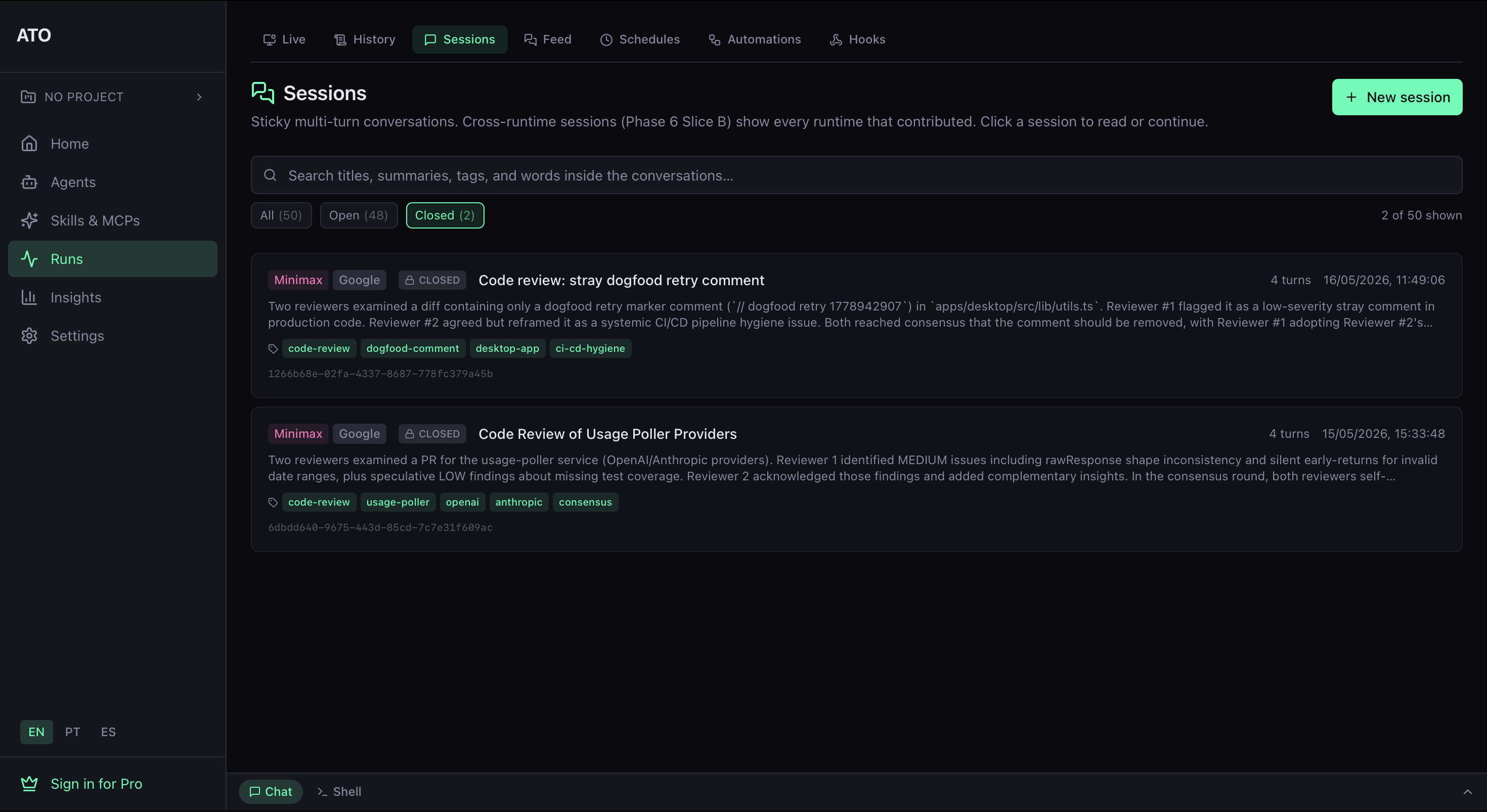
Cada dispatch multi-LLM cae en tu SQLite local como una sesión que puedes revisar después. Cada fila lleva un resumen auto-generado, los runtimes que hablaron, las personas (cuando usaste --agent), tags y un session id que puedes pasar a ato sessions get desde tu terminal. Sin cuentas, sin round-trip a la nube — todo en la máquina del desarrollador.